Tencent Releases HY-Motion 1.0, a Breakthrough in Text-to-3D Human Motion

- HY-Motion 1.0 scales Diffusion Transformer models to a billion parameters for the first time in 3D motion generation, with open access to code, models, and tooling.
- The system spans 200+ motion types and uses a multi-stage training process to improve accuracy and realism.
Tencent has open-sourced HY-Motion 1.0, a new family of models that generate 3D human motion from text prompts. Built on Diffusion Transformers and Flow Matching, Tencent says it is the first model of its kind to reach a billion parameters, enabling more precise prompt interpretation and more lifelike animations than existing open models. With it, developers can generate skeleton-based 3D character animations from text prompts, with results ready for use in a variety of 3D animation pipelines.
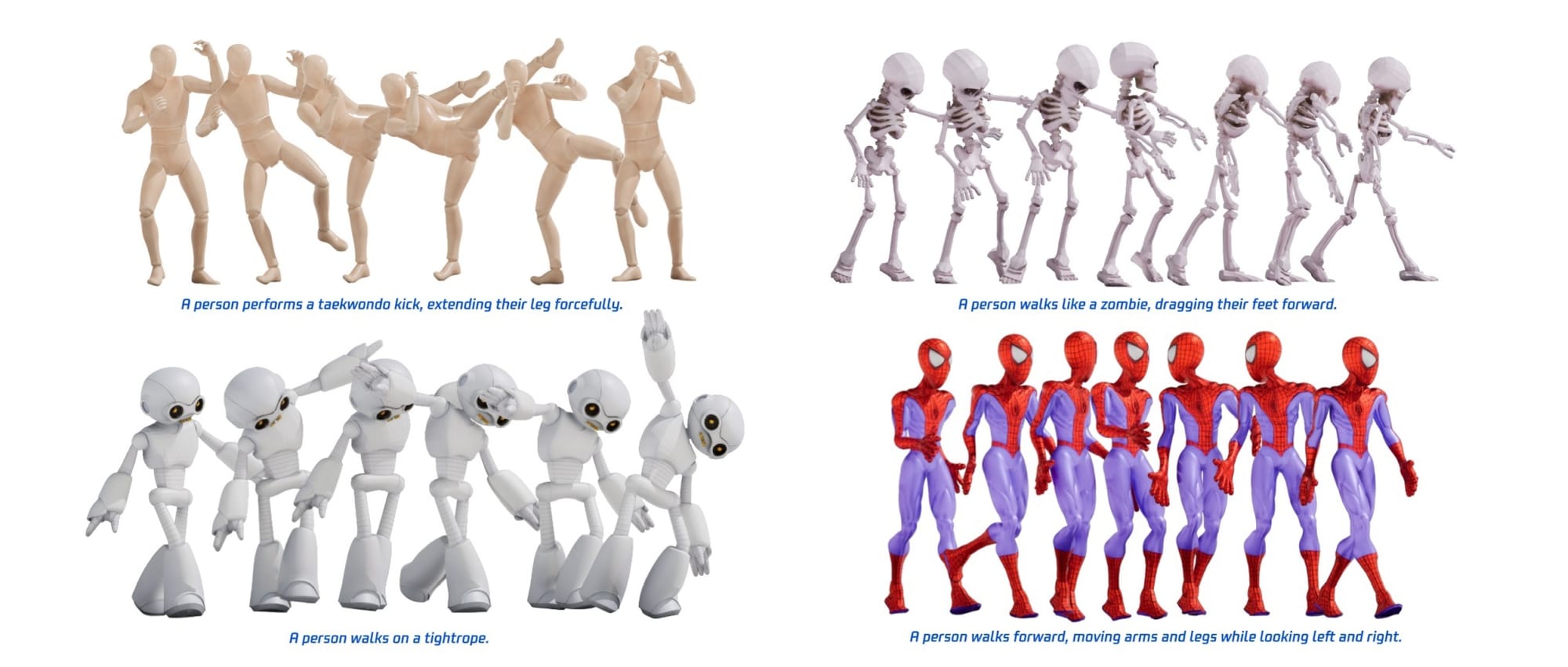
According to the accompanying research paper, the training process consisted of three distinct phases, beginning with over 3,000 hours of pretraining on diverse motion data. This was followed by fine-tuning on 400 hours of curated, high-quality sequences and further refinement using human feedback and reward models. Tencent claims this full-stage approach contributes to state-of-the-art performance in both prompt alignment and motion quality. Combined with a custom data pipeline for motion cleaning and captioning, the billion-parameter model is able to learn over 200 motion types spanning six major motion categories.
HY-Motion 1.0 is now open-sourced on GitHub and Hugging Face, with both standard and lightweight models included. The release comes with a command-line tool for batch inference and a Gradio app for interactive use. Tencent writes that the release is meant “to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.”
🌀 Tom’s Take:
Scaling to a billion parameters isn’t just a flex. It’s what unlocks sharper prompt understanding and more lifelike motion, setting a new bar for open-source text-to-3D systems.
Source: Hugging Face / Tencent



